Menu aplikace
Hlavní menu aplikace se skládá ze 6 základních položek, které se dále dělí. Mezi těchto 6 položek patří:
⇒ Číselníky
⇒ Soubory
⇒ Případy
⇒ Prohlížení
⇒ Sestavy
⇒ Administrace
Číselníky
Menu číselníky slouží k prohlížení a zpracování číselníků, které aplikace využívá. V současné době aplikace umožňuje prohlížení (P) a zpracování (Z) následujících číselníků :
· Výkony (P,Z - VZP)
· HVLP (P,Z - VZP)
· IVLP (P,Z - VZP)
· Pomůcky zdravotnické techniky (P,Z - VZP)
· Stomatologické výrobky (P,Z - VZP)
· Doprava (P,Z - VZP)
· Odbornost (P,Z - VZP)
· Diagnózy (P,Z - VZP)
· Kategorie pacienta (P,Z - VZP)
· Doporučení k hospitalizaci (P,Z - VZP)
· Náhrady (P,Z - VZP)
· Ukončení léčení (P,Z - VZP)
· Číselník poboček VZP (P,Z - VZP)
· Cenová pásma (P,Z - VZP)
· Druhy dokladů (P,Z - VZP)
· Položky řádků klinických dat (P - INT)
· Druhy dávek (P,Z - VZP)
· Zdravotní pojišťovny (P,Z)
· Číselník relativních vah DRG (P,Z - INT)
· Číselník BASE DRG (P - INT)
· Vazba Ičp na oddělení (P,Z - GIT)
Číselníky VZP (označení VZP)
Jedná se o číselník distribuovaný Všeobecnou zdravotní pojišťovnou.
Interní číselníky (označení INT)
Číselník je dodáván současně s instalací.
Aktualizace číselníků se provádí vždy při změně některé z položek a to v nejbližším možném okamžiku.
Číselník BASE DRG – číselník DRG skupin;
Číselník relativních vah DRG – číselník relativních vah DRG platných pro konkrétní období;
Vazba Ičp na oddělení - číselník je vytvořen na základě organizační struktury zdravotnického zařízení.
Číselníky s označením GIT
Číselník, který je generován z dat zdravotnického zařízení, kde je systém instalován.
Prohlížení a vyhledávání v číselnících
Prohlížení číselníků je uživateli zpřístupněno rolí „Prohlížení číselníků“. Pomocí této stránky lze v číselnících na základě zvolených kritériích vyhledávat.
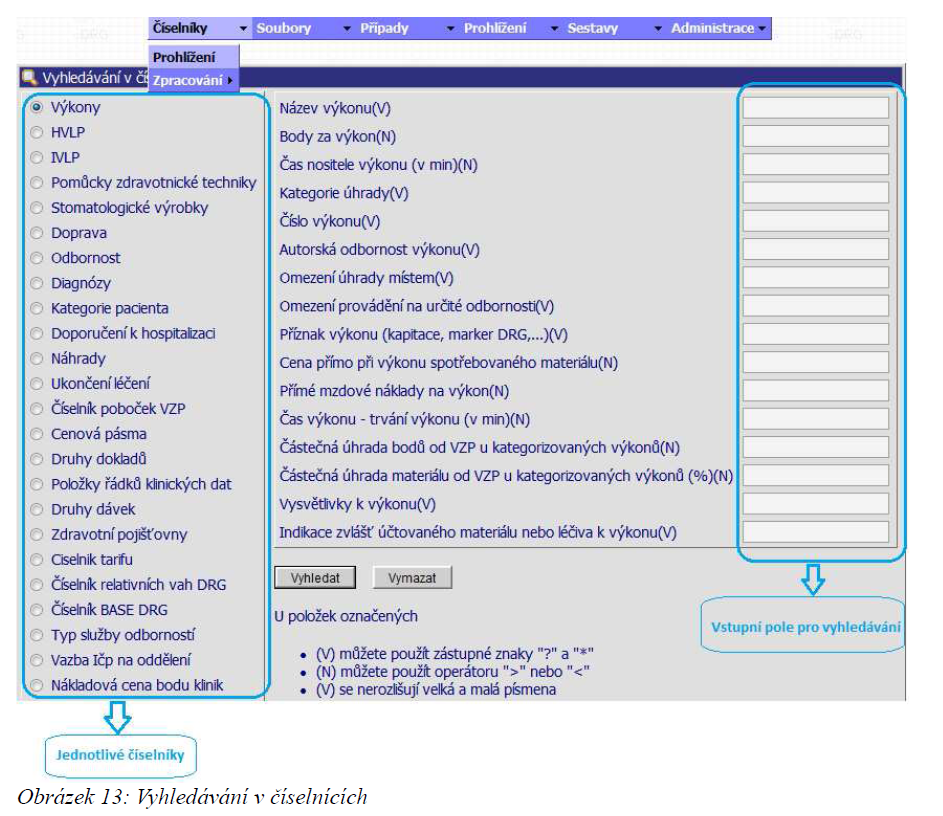
Po zvolení číselníku jsou nad tlačítkem [ Vyhledat ] zobrazeny vstupní pole, dle kterých je možno v číselníku hledat. Množství a typy vstupních polí se dynamicky mění v závislosti na zvoleném číselníku z tabulky vlevo.
Označení V, N a D uvedené za názvem pole v závorkách označuje, zda se jedná o numerické(N), textové pole (V) či o datum (D).
Vyhledávání v položkách typu V
Nebere ohled na velká a malá písmena, dotazy typu „ičp“, „Ičp“ či „IČP“ vrátí tedy vždy stejný výsledek.
Vyhledávání v položkách typu D
Předpokládá se zadávání data ve formátu DD.MM.YYYY. Je možné použít zkrácený zápis vstupních hodnot ve formátu DDMMYY. To znamená, že pokud chceme do kolonky datum zadat např. 31. 12. 2009, stačí při zadávání vložit 311209 a aplikace automaticky zformátuje zadaná čísla na správné datum. Aplikace v této fázi neprovádí kontrolu data na správnost zápisu, proto při zadání číslic např. 454545 zformátuje datum na 45.45.1945. Po stisknutí tlačítka [ Vyhledat ] ale aplikace zkontroluje všechna zadaná data, a nekorektní datum označí jako chybně zadané.
Do vstupních políček je možné používat následující vyhledávací operátory:
„?“ - pro nahrazení jednoho znaku v řetězci (pro textové položky)
„*“ - pro nahrazení jednoho a více znaků v řetězci (pro textové i numerické položky)
„>“, „<“, „>=“, „<=“ – pro porovnání hodnot atributu (pro numerické položky).
U všech položek lze podmínky řetězit, a to buď pomocí oddělení čárkou (nahrazuje logickou vazbu „A“) nebo středníkem (nahrazuje logickou vazbu „NEBO“).
Příklad: Pokud chceme zobrazit záznamy s položkou Případ větší jak 100 a menší nebo rovno 1000 bude výsledný zápis podmínky vypadat následovně:

V případě vyplnění více polí je mezi jejich hodnotami provedeno logické spojení operátorem Příklad vyhledávání s více podmínkami „A“. To znamená, že budou vybrány pouze ty položky číselníku, které splňující všechny zadané podmínky.
Jakmile zadáme podmínky pro vyhledání záznamu, stiskneme tlačítko [ Vyhledat ]. Aktuální tabulka se překreslí a jejím obsahem budou záznamy odpovídající zadané podmínce. Pokud ovšem nějaká z podmínek nesplňuje správný vstupní formát (např. chybně zadané datum, písmena v číselné položce atp.), zobrazí se přímo pod špatně zadanou položkou varovný text informující o chybě a typu chyby v položce. Pokud nebyla zadána do vyhledávacích polí žádná podmínka, zobrazí se VŠECHNY záznamy k danému číselníku.
Pro vymazání zadaných podmínek slouží tlačítko [ Vymazat ], které provede vymazání všech vstupních polí v tabulce vpravo.
Tlačítkem [ Logout ] se provede odhlášení z aplikace, tlačítkem [ Zpět ] se aplikace vrátí na předchozí stránku s vyhledáváním.
Přehledová tabulka číselníků
V praxi je zcela běžné, že tabulky mají stovky řádků. Bylo by náročné a nepřehledné zobrazovat na obrazovku všechny řádky. Proto je zvolen přístup zobrazení jen určitého počtu (dávky řádků). Na obrazovce je vždy zobrazena jen jedna dávka, např. 20 řádků.
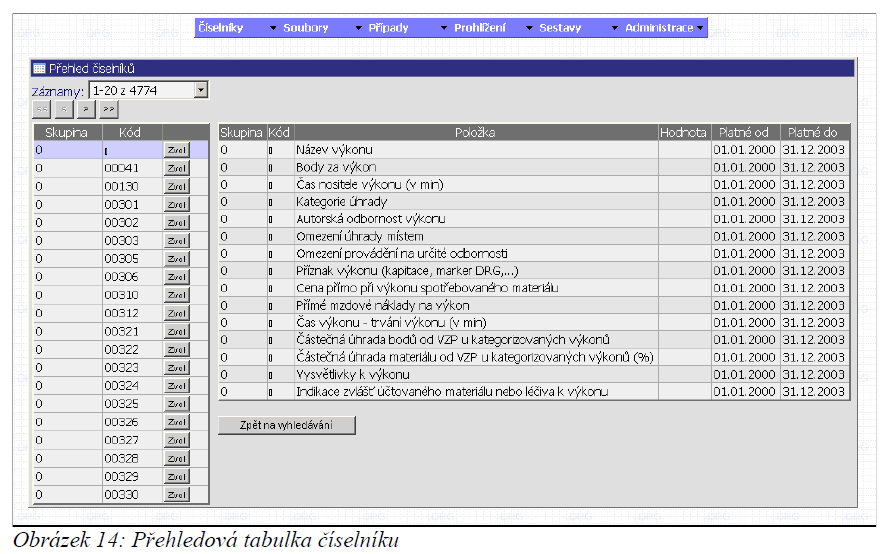
V rámci tabulky se lze pohybovat mezi jednotlivými dávkami řádků či zobrazovat detaily pro jednotlivé řádky. Pro zobrazení dat pro jednotlivé řádky slouží tlačítko [Zvol].
Následující navigační prvky se využívají pro pohyb mezi skupinami řádků po dvaceti:
[ << ] – přesune se na první skupinu záznamů;
[ < ] – přesune se na předchozí skupinu záznamů;
[ > ] – přesune se na následující skupinu záznamů;
[ >> ] – přesune se na poslední skupinu záznamů.
Pokud některé tlačítko není logicky potřeba (Na první stránce záznamů jsou to např. tlačítka [ << ] a [ < ]), je zašedlé a nefunkční).
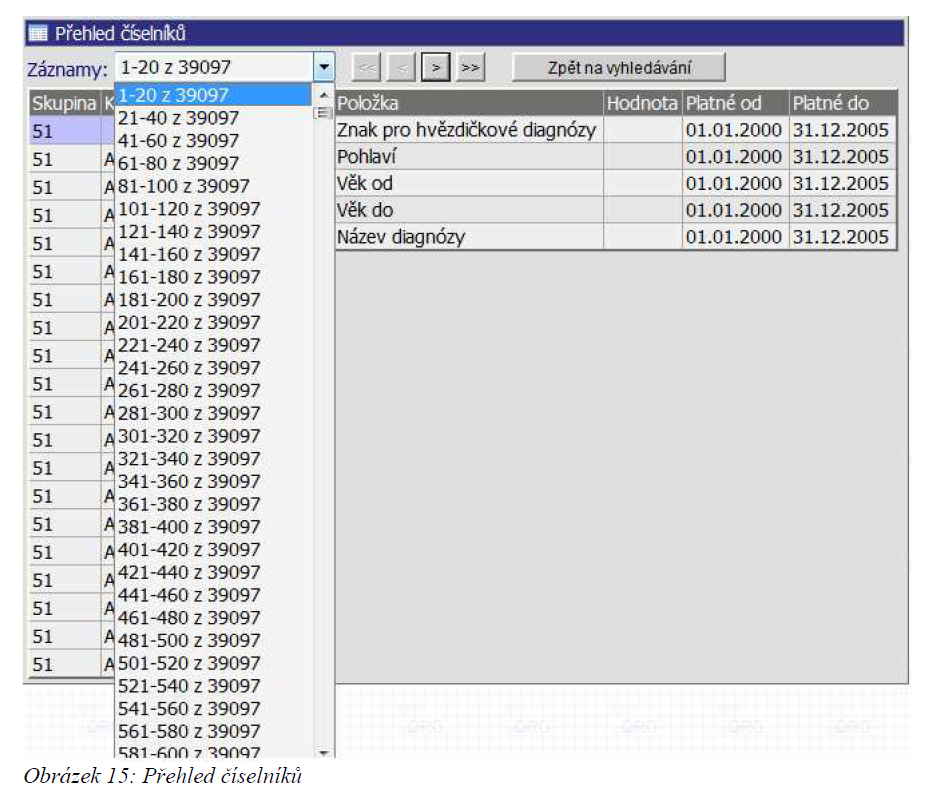
Na jakoukoliv stránku záznamů se také lze dostat pomocí interaktivního rozbalovacího seznamu záznamů (za titulkem Záznamy, viz. následující obrázek).
Zpracování
Zpracování datového souboru (číselníku) se provádí pomocí formuláře, který nalezneme v menu pod položkou Číselníky → zpracování. Podle typu dat, které jsou obsahem souboru,
vybereme příslušný typ číselníku (např. výkony, diagnózy apod.).
Do systému lze zpracovávat jak jeden konkrétní soubor tak více souborů najednou, které však musí být zkomprimovány metodou ZIP do jednoho jediného souboru (ZIP archívu).
ZIP archív nesmí obsahovat adresáře. Každému souboru musí být nadefinováno datum platnosti!
Každému zpracování v systému je přiděleno unikátní číslo, které slouží k jedinečné identifikaci a orientaci ve zpracování.
Soubory
Pomocí této položky v menu je prováděno:
- zpracování vstupních souborů výkonových dat od zdravotnických zařízení;
- výmaz souboru dávek.
Dávky výkonů ZZ
Filosofie zpracování datových souborů je stejná jako zpracování číselníků (výběr souboru, zvolit typ zpracování).
Do systému mohou vstupovat soubory klinických dat typu KDAVKA v datovém rozhraní VZP 6.0 nebo 6.2. Tyto soubory musí být zabaleny pomocí zip komprese v jednotlivých adresářích, které identifikují období, za které byla klinická data předána zdravotní pojišťovně k vyúčtování.
Vstup dat KDAVKA z nemocničního systému NIS
Filosofie zpracování je stejná jako u jiného zpracování, tj. možnost zvolení typu zpracování, definování dalších parametrů zpracování a apod. s tím rozdílem, že zpracování není prováděno z datových souborů, ale data jsou „přelívána“ přímo z nemocničního systému konkrétního zdravotnického zařízení.
Výmaz souborů
Filosofie mazání datových souborů je stejná jako pro zpracovávání souboru, jen zde chybí pole pro volbu vstupního souboru, naopak se definuje období, za které se mají soubor/y smazat.
Výmaz má za následek:
- Výmaz primárních dat nahraných z klinického informačního systému nebo ze souborů ve formátu KDAVKA a výmaz o chybách při zpracování těchto souborů;
- Výmaz informací o případech hospitalizace a jejich zagroupování. Vymazány jsou všechny případy, jejichž součástí je některý z vymazávaných dokladů. Případy jsou vždy vymazány jako celek. Nejsou mazány informace o zpracování souborů a o jednotlivých jobech zpracování.
Případy
Tato volba je určena k práci s přehledovým formulářem sloužícímu k prohlížení sestavených případů hospitalizace.
Sestavení případů
Pomocí tohoto formuláře lze spouštět sestavení případů z hospitalizačních dokladů jednotlivých IČZ pro zvolené období. Algoritmus sestavení případu je poplatný aktuální metodice výpočtu sestavení případu dle NRC DRG.
Přiřazení DRG
Formulář slouží ke spuštění procesu přiřazování sestavených případů hospitalizace do odpovídajících DRG skupin. Případ je zařazen do odpovídající DRG skupiny pomocí definičního manuálu DRG programem GROUPER DRG, který je poskytován NRC DRG.
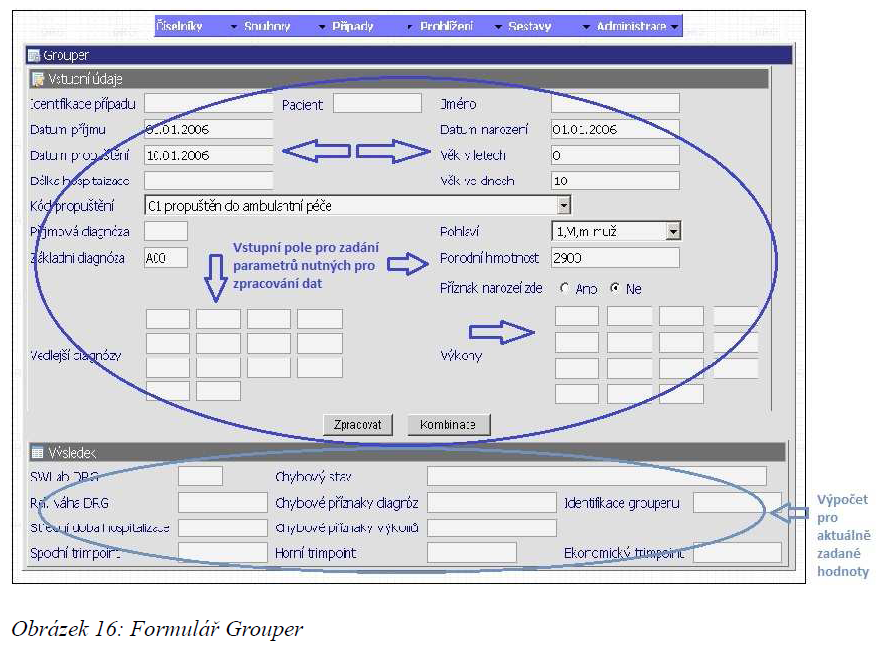
Grouper
Pomocí formuláře grouper dochází k řazení případů do jednotlivých DRG skupin a k výpočtům hlavních ukazatelů jako je relativní váha DRG, střední doba hospitalizace, trim-pointy apod. Je tvořen dvěma částmi.
- Horní část obsahuje vstupní pole pro vyplnění základních parametrů nutných pro zpracování dat. Do těchto polí vstupují údaje o hospitalizaci, čili atributy případu (věk, pohlaví, hlavní a vedlejší diagnózy, atd.).
- Druhá část je tvořena výstupními poli, ve kterých jsou zobrazována data vypočtená pro aktuálně zadané hodnoty ve vstupních polích.
Formulář nabízí dvě možnosti zpracování. První možností je samotný výpočet pomocí tlačítka [ Zpracovat]. Další možností je zobrazení zagroupování případu hospitalizace při případné záměně jednotlivých vedlejších diagnóz za diagnózu základní. Pro vstup do formuláře pro záměnu diagnóz je určené tlačítko [Kombinace].
V datumových položkách grouperu lze používat zkrácené zadávání data ve formátu DDMMYY.
Sestavené případy – doklady
Tato volba zobrazí tabulku sestavených případů s důležitými údaji pro každý jednotlivý případ (DRG, typ, relativní váha apod.) a k nim detailní tabulku dokladů příslušejících ke každému jednotlivému případu.

Tabulka sestavených případů obsahuje následující údaje:
Případ – interní kód případu;
IČZ – identifikační číslo zdravotnického zařízení;
Z – identifikace zdroje dat (P - KDAVKA);
Pacient – číslo pacienta;
Přijat – datum přijetí pacienta;
Propuštěn – datum propuštění pacienta;
Verze – verze sestavení případu, měla by odpovídat verzi grouperu;
Dg – diagnóza případu;
UK – důvod ukončení případu;
Body – body za případ;
Kč ;
DRG;
Typ – typ groupování ( R – referenční období, C – současné období);
RV – relativní váha případu;
Rozdíl RV – rozdíl mezi optimální a vykázanou relativní váhou ;
ZP – zdravotní pojišťovna jíž byl odevzdán propouštěcí doklad pacienta;
Optimální DRG – DRG s nejvyšší relativní vahou, získanou, kombinací hlavní a
vedlejších diagnóz;
Optimální alfa;
Optimální paušál;
Inlier – Příznak zda doba hospitalizace je v intervalu spodního a horního trimpointu; -1 – spodní outlier; 0 – inlier; 1 – horní outlier;
Ičp – propouštěcí Ičp (identifikační číslo propuštějícího pracoviště);
Klinika;
Typ úhrady – typ úhrady dle úhradové vyhlášky MZ.
Kliknutím na libovolný řádek v tabulce případů se daný případ zvýrazní a ve spodní tabulce se zobrazí detailní data dokladů pro zvolený řádek. U detailu případu je zobrazen přehled všech dokladů příslušejících kdanému zvolenému případu.
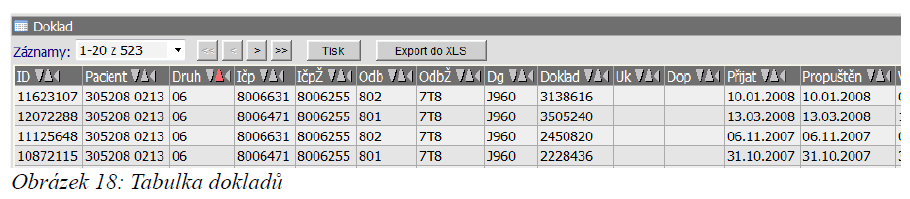
Tabulka s detailem na jednotlivé doklady případu obsahuje následující údaje:
ID – interní kód;
Pacient – číslo pacienta;
Druh – Druh dokladu;
Ičp – klinika;
IčpŽ – klinika žadatele;
Odb – odbornost poskytujícího;
Odb – odbornost žadatele;
Dg – diagnóza;
Doklad – číslo dokladu;
Uk – důvod ukončení;
Dop – doporučení k hospitalizaci;
Přijat – datum přijetí pacienta;
Propuštěn – datum propuštění pacienta;
Vystaveno – datum vystavení poukazu;
V – příznak vyloučené položky z dalšího zpracování.
U každého dokladu je na konci funkční tlačítko [ Řádek ], které po kliknutí zobrazí samostatný formulář se seznamem všech řádků příslušejících k danému dokladu.
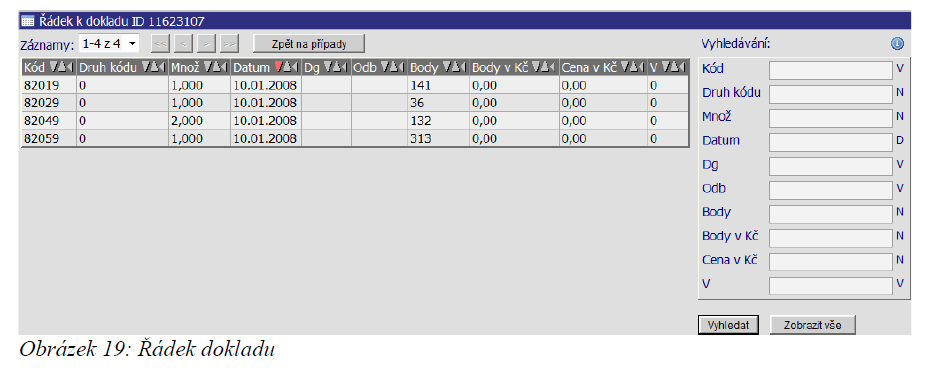
Tabulka se seznamem všech řádků daného dokladu obsahuje následující údaje:
Kód – kód výkonu, léčiva či materiálu;
Druh kódu – určení zda se jedná o výkon, léčiva či materiál ;
0 – výkony; 1 – HVLP, 2 – IVLP, 3 – PZT, 4 – stomatologické výrobky;
Množ – počet výkonů nebo množství podaného léčiva/materiálu;
Datum – datum provedení/poskytnutí;
Dg – diagnóza;
Odb – odbornost poskytujícího;
Body – cena výkonu v bodech;
Body v Kč – cena výkonu v bodech přepočtená na koruny;
Cena Kč – cena léčiv a materiálu v korunách;
V – příznak vyloučené položky z dalšího zpracování4.
V rámci sestavených případů je také možné vyhledávání případů s konkrétními parametry. K tomuto účelu slouží formulář v pravé části obrazovky.
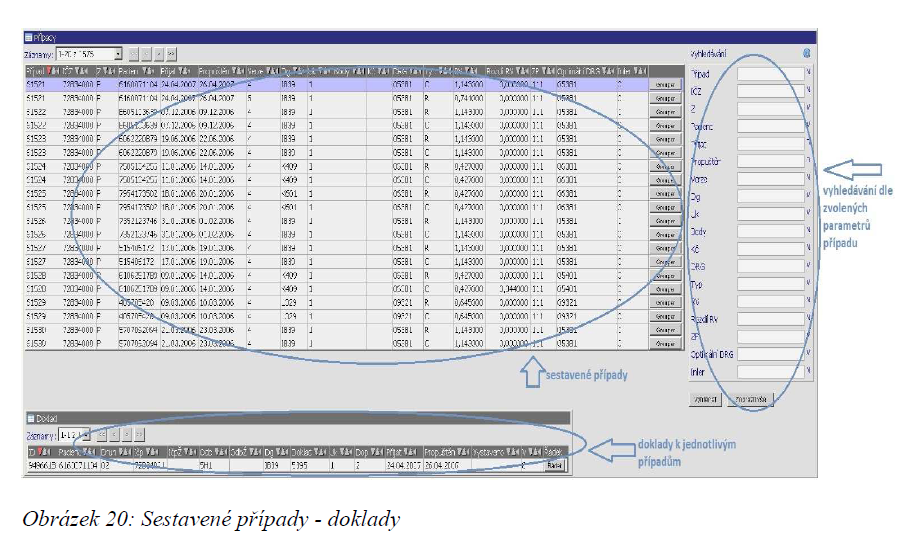
V obou těchto tabulkách lze využít řazení dle zvoleného sloupce pomocí malých šipek v záhlaví tabulky vedle (nebo pod, záleží na délce nadpisu) nadpisu každého sloupce. Vybraná volba je indikována zvýrazněním šipky červenou barvou.
Pokud se provede kliknutí na červeně označenou šipku, vypne se třídění pro celou tabulku.
V záhlaví každého sloupce se dále nachází minimalizační šipka (viz. Obrázek 21). Ta slouží k dočasnému minimalizování sloupce (jeho skrytí). Funkce slouží ke zpřehlednění orientace v tabulkách s mnoha datovými sloupci, kdy si uživatel může sloupce libovolně minimalizovat/maximalizovat a tak si vzhled tabulky přizpůsobit potřebám zobrazení.
Minimalizovat lze libovolný počet sloupců v přehledové tabulce. V každém řádku tabulky sestavených případů můžeme nalézt tlačítko [ Grouper ], po jehož aktivaci, se zobrazí formulář grouperu s předvyplněnými daty pro daný případ (obrázek 22). Je tedy možné provádět nad daným případem kombinace či přehledové a zkušební výpočty pro každý případ tabulky.
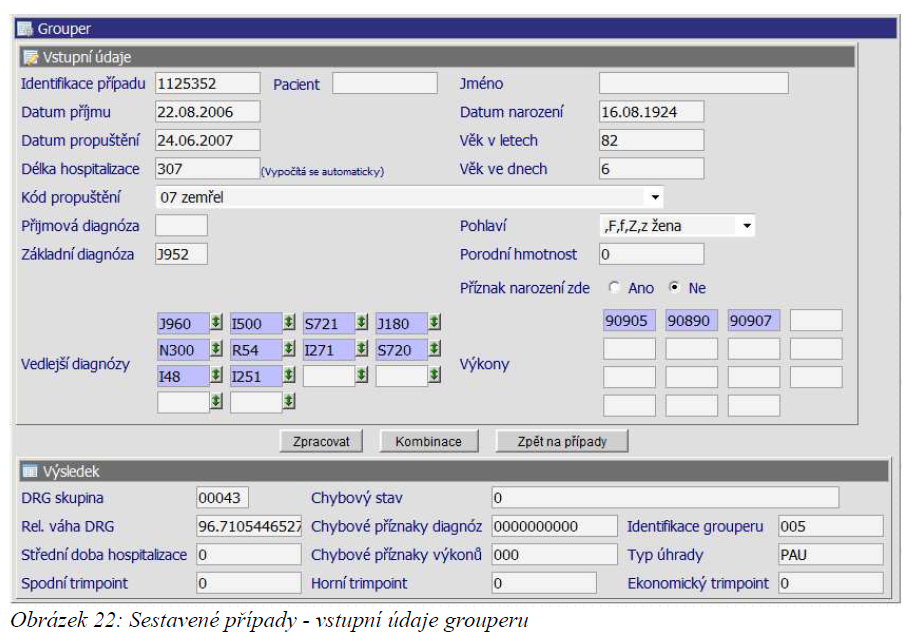
U pole Příjmová diagnóza, základní diagnóza, vedlejší diagnózy, výkony a DRG skupina, lze pomocí najetí myši na jednotlivé kódy zjistit konkrétní názvy diagnóz, výkonů či DRG skupiny.
Prohlížení
Tato položka menu umožňuje uživateli přístup k jednotlivým dávkám a dokladů k nim příslušejícím, k úvodním grafům aplikace a také k modulu ROLAP.
Dávky
Jak už název položky menu napovídá, tento formulář slouží k prohlížení dávek a dokladů k nim příslušejícím. Jeho funkce je obdobná jako funkce formuláře zobrazující případy/doklady/řádky. Formulář zobrazuje jednotlivé dávky v horní části a veškeré doklady zvolené dávky v dolní části. Součástí je i formulář umožňující vyhledávání podle zvolených parametrů dávky.
Úvodní grafy
Pomocí této položky menu se uživatel dostane na úvodní stranu aplikace, která obsahuje grafy zobrazující počet případů hospitalizace, casemix index, vykázané body a náklady na léčiva a PZT pro jednotlivá období vykázání.
ROLAP
Modul ROLAP systému SWLab-DRG slouží pro zobrazení dat pomocí uživatelské definice tabulek a grafů.
Poskytuje náhled na data o případech akutní hospitalizace formou tzv. multidimenzionálních kostek. Volbou dimenzí a filtrů lze definovat požadované řezy a získávat tak statistiky vybraných ukazatelů.
Dimenze jsou hierarchicky strukturované číselníky – např. Období (Rok, pololetí, čtvrtletí, měsíc), DRG (MDC, BASE, DRG) apod.
Statistikami ukazatelů se rozumí počet, minimum, maximum, průměr a součet vykázaných bodů, ošetřovací doby, nákladů na ZUM a ZULP apod.
Modul po spuštění vypadá následovně:
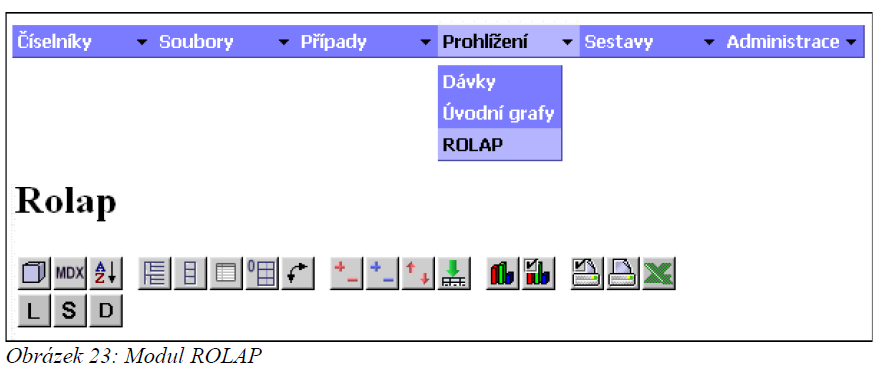
Modul ROLAP se ovládá pomocí lišty tlačítek, jejichž význam si teď vysvětlíme.
Otevření dotazu (load)
Zobrazí panel pro otevření dříve vytvořené definice dotazu. Při výběru dotazu (např. DRGALFAV viz Obrázek níže) se nám objeví výsledná tabulka s daty, které odpovídají definici zvoleného dotazu.

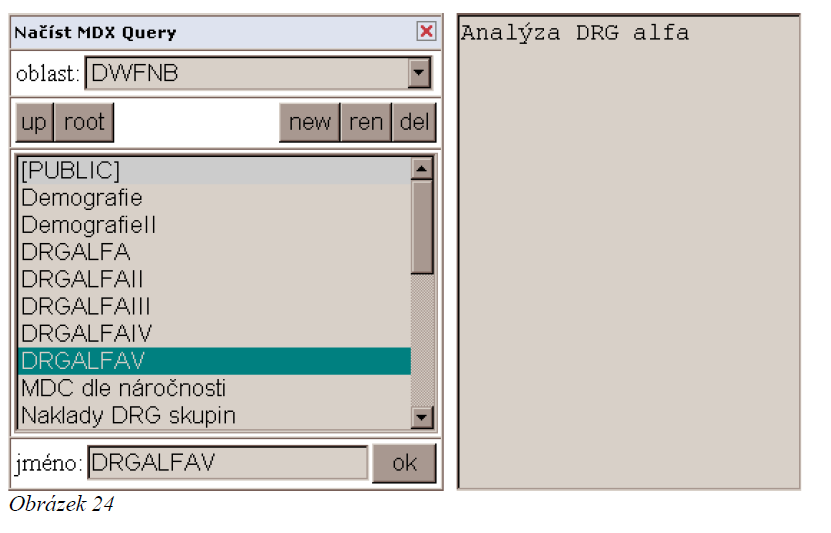
Vytvoření nového dotazu (load)
Umožní vytvořit nový dotaz otevřením a úpravou jiného již uloženého dotazu. Funkce je stejná jako při otevření dotazu, pro tento účel jsou ve složce "PUBLIC" připraveny dotazy: "Nový - počet případů" a "Nový – produkce".
Uložení dotazu (save)
Umožní uložit aktuální definici dotazu pro pozdější použití. [ ok ] – uloží definici dotazu s názvem 'jméno', který se musí odlišovat od dotazů již uložených ve stejné složce.
Uložení popisu dotazu (description)
Umožní uložit popis k aktuálnímu (již uloženému) dotazu.
[ Obnovit ] – obnoví popis uloženého dotazu.
[ Uložit ] – uloží popis aktuálního dotazu.
atd.
Sestavy
Menu sestavy slouží pro spouštění předdefinovaných sestav a jeho obsah je závislý na typu instalace aplikace a počtu sestav definovaných pro aplikaci. Obsahuje seznam předdefinovaných sestav, přičemž po kliknutí na položku sestavy se zobrazí spouštěcí formulář vybrané sestavy.
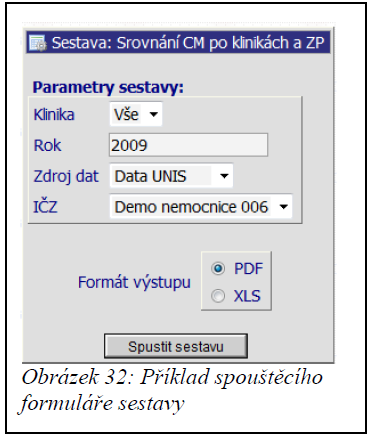
Počet a typ parametrů, které se dají v rámci sestavy nastavit je pro každou jednotlivou sestavu specifický. V každé sestavě je však možnost zvolit zdroj dat a IČZ.
Aplikace umožňuje tvorbu dvou hlavních typů výstupů, které závisí na formátu sestavy. Pro tisk, prezentaci a prohlížení umožňuje vytvářet sestavy ve formátech PDF a XLS, pro následné zpracování dat poté ve formátech DBF (Dbase III) a CSV. Při výstupu ve formátu DBF a CSV umožňuje formulář spuštění sestavy zvolit volbu kódování češtiny, která se ve výsledném datovém souboru použije na textové popisy obsahující české znaky (typicky popisy diagnóz, výkonů apod.).
Po stisknutí tlačítka [ Spustit sestavu ] se spustí generování dané sestavy dle zvolených vstupních dat formuláře. Po vygenerování sestavy se zobrazí odkaz s možností stáhnutí/zobrazení dané aktuálně vygenerované sestavy a zároveň se sestava uloží do databáze, pro případné budoucí prohlížení/stažení.
Zpracování některých složitějších sestav s hodně parametry může trvat i několik desítek minut!
Přehled sestav
Jedná se o formulář obsahující seznam všech vygenerovaných sestav. V tabulce detailu jsou zároveň zobrazeny všechny parametry sestavy s takovými hodnotami, s jakými byla daná sestava spuštěna.
V přehledové tabulce lze navíc kliknutím na název jakékoliv sestavy zobrazit samostatné okno s danou sestavou.
Pro zobrazení sestav je třeba mít povoleno zobrazování pop up oken pro http adresu aplikace!
Popis jednotlivých sestav
Aplikace může obsahovat až desítky různých sestav v závislosti na typu instalace. Často také dochází k vytváření a přidávání sestav nových, podle požadavků uživatele. Proto si v této kapitole uvedeme jen několik základních sestav.
Ičp podílející se na DRG
Sestava zobrazuje počty případů a jejich délky, zařazené do DRG báze za vybrané období a kliniku. Parametry sestavy je tak období a klinika za níž jsou výstupní data filtrována. Samotná sestava pak obsahuje oddíly po jednotlivých bázích DRG, které jsou řazeny podle četnosti jejich výskytu.
O DRG bázi jsou v sestavě zobrazovány tyto informace:
Statistické informace o případech zařazených do DRG báze:
o Case mix – průměrná váha případů zařazených do této DRG báze
o Počet případů – počet případů hospitalizace v absolutním počtu a procentuálním vyjádření v členění na případy BEZ CC, S CC, S MCC (bez komplikací, s komplikacemi a významnými komplikacemi)
Sestava obsahuje také informace o IČP podílejících se na léčení jednotlivých případů hospitalizace, seřazených dle atributu informujícího, zda pracoviště bylo propouštějícím pracovištěm případu (označeno v sestavě X), či zda se na péči o případ jen podílelo v jeho průběhu (bez označení). Dále jsou pracoviště seřazeny podle počtu případů, které ošetřily.
Sestava podává ucelený pohled na nejčastěji ošetřované DRG báze v rámci nemocnice, jejich ohodnocení pomocí casemix indexu a na pracoviště, která se rozhodným způsobem na jejich léčbě podílí.
Výkaz pacienta
Sestava Výkaz pacienta slouží pro podrobný pohled na veškeré výkony, které byly pacientovy provedeny. Jedná se o detailní přehled všech vykázaných dokladů na všech pracovištích. Vstupními parametry sestavy je číslo pacienta, zdroj dat a IČZ. Výstupem je tabulka, se všemi vykázanými doklady daného pacienta, s přehledem vykázaných výkonů a zvlášť účtovaných léků a zdravotnických prostředků.
Pacienti dražší než parametry
Sestava informuje o pacientech, kteří jsou podle úhradové vyhlášky hrazeni zvlášť. Výstupem jsou tedy pacienti, kterým byla poskytnuta dražší péče než zvolená hodnota . Ve většině případů se jedná o pacienty s péčí dražší než 1 mil. Kč. Parametry sestavy jsou datum od-do, zdroj dat, IČZ vybraného zařízení, cena bodu (pro výpočet je nutné zadat hodnotu bodu pro ocenění bodové složky úhrady) a minimální cena.
Výstupem je tabulka se seznamem pacientů, kteří splňují dané parametry. U každého pacienta je uvedena cena v bodech (sloupec Body), součet nákladů za zvlášť účtované léky a materiál (sloupec Cena) a cena celkem. Celková cena představuje součet nákladů na léky a materiál a Bodů vynásobených zadanou cenou bodu.
Případy pacienta
Sestava slouží k zobrazení veškerých případů konkrétního pacienta v daném zařízení. Výstup představují základní informace o případu jako je datum přijetí a propuštění, základní diagnóza, způsob ukončení, typ grouperu a relativní váha případu. Jako parametr pro filtraci výstupních dat zde slouží číslo pacienta.
Srovnání RV případů
Sestava zkoumá jednotlivé případy hospitalizace, provádí záměnu základní a vedlejších diagnóz případu a vyhodnocuje vliv této záměny na určení relativní váhy případu. Sestava má dva parametry a to počáteční a koncové datum propuštění případů, za něž má být spuštěna.
UPOZORNĚNÍ: Sestava pouze indikuje možnost jiného, lepšího vykázání případu. Změny v ní indikované musí být schváleny lékařem jakožto popisujícím skutečný stav a musí být zaznamenány v lékařské dokumentaci.
V sestavě jsou uvedeny následující údaje:
Id. případu – jednoznačná identifikace případu v aplikaci
Původní RV – váha případu v podobě jak byl původně zakódován
Nejvyšší dosažitelná váha – nejvyšší váha případu dosažitelná záměnou základní a vedlejších diagnóz případu
Rozdíl vah – rozdíl mezi původní a nejvyšší dosažitelnou vahou případu
Sestava slouží jako indikátor možných neoptimálně zakódovaných případů. Případy v ní uvedené je vhodné vyhledat pomocí funkce „vyhledávání“ ve formuláři Sestavené případy. V tomto formuláři si pak lze na konkrétním případu (pomocí tlačítka grouper) prohlédnout původní zakódování případu a případně pomocí tlačítka „Kombinace“ následně zhodnotit, která z popsaných kombinací nejlépe popisuje skutečný stav pacienta.
Diagnózy na dokladech
Sestava zobrazuje počty diagnóz na hospitalizačních dokladech vykázaných jednotlivými pracovišti. Sestava je členěna po jednotlivých klinikách a jejich pracovištích.Záznam pro každé pracoviště je rozdělen na dvě části pomocí příznaku X ve sloupci propouštěcí, který indikuje zda byl výpočet proveden pro doklady uzavírající hospitalizaci či zda byl proveden pro doklady vykázané při přijetí či v průběhu léčby. Parametry sestavy jsou data sledovaného období od a do.
Casemix nemocnice
Sestava zobrazuje hodnotu casemix indexu a počtu případů nemocnice jako celku za zadané období po jednotlivých měsících. Parametrem sestavy pro výstupní data je sledované období (tzn. Datum od-do).
Casemix klinik
Sestava zobrazuje hodnotu casemix indexu a počty případů klinik v jednotlivých měsících sledovaného období. Parametrem sestavy podle něhož jsou filtrována výstupní data je datum (časové rozmezí od-do).
Srovnání CM za nemocnici
Sestava slouží ke sledování plnění parametrů úhradové vyhlášky. Je členěna po jednotlivých zdravotních pojišťovnách a obsahuje kumulativní hodnoty počtu případů a casemixu za jednotlivé měsíce a jejich srovnání s hodnotami referenčními. Parametrem sestavy, podle něhož jsou filtrována výstupní data je rok.
Srovnání CM dle kliniky
Sestava slouží ke sledování parametrů casemixu a počtu případů jednotlivých klinik. Zobrazeny jsou kumulativní hodnoty za jednotlivé měsíce.
Srovnání CM dle kliniky a ZP
Sestava slouží ke sledování parametrů casemixu a počtu případů jednotlivých klinik za zdravotní pojišťovny. Zobrazeny jsou kumulativní hodnoty za jednotlivé měsíce dle jednotlivých zdravotních pojišťoven.
Frekvence výkonů
Sestava slouží pro zobrazení četnosti výkonů za vybrané pracoviště a odbornost. Výstupem je tabulka, která obsahuje informace o počtu provedení jednotlivých výkonů, kód příslušného výkonu, odbornost a dále cenu výkonu a přímého materiálu. Data lze filtrovat na základě parametru datum od-do, odbornosti a IČP.
Frekvence materiálu
Sestava zobrazuje detail na použitý materiál. K jednotlivým výkonům je zde uvedeno množství spotřebovaného materiálu, o jaký materiál se jedná (HVLP, IVLP, PZT, stomatologické výrobky) a celková cena materiálu.
Druh jednotlivých materiálu je označen kódem HVLP – 1, IVLP – 2, PZT – 3 astomatologické výrobky mají označení 4. Parametrem sestavy jsou shodné s parametry sestavy frekvence výkonů. Data lze tedy filtrovat na základě parametru datum od-do, odbornosti a IČP.
Poměr ocenění
Sestava porovnává výkonové hodnocení případů a hodnocení na základě DRG za jednotlivá pracoviště (IČP), případně i za jednotlivé případy vybraného zařízení. U výkonového hodnocení je zobrazena celková výše bodů za IČP vynásobená aktuální cenou bodu, ZUM a jejich součet, u DRG pak relativní váha případů a cena. Cena u hodnocení DRG je počítána jako součin základní sazby a relativní váhy.
Parametry sestavy je datum od-do, typ případu (lze vybrat pouze případy s překladem či bez překladu), předpokládaná cena bodu, základní sazba a tisk případů.
Parametr Tisk případů umožňuje zobrazit ve výstupu pouze hodnocení za jednotlivá IČP . V případě nastavení tohoto parametru na možnost „S jednotlivými případy“, jsou zobrazeny veškeré informace nejen pro jednotlivá IČP, ale i pro konkrétní případy
Administrace
Tento modul slouží pro správu aplikace. Zajišťuje jednak prohlížení systémových logů, správu uživatelů, definici přístupových práv jednotlivých uživatelů a dále spouštění exportu databáze jako prostředku pro pravidelné zálohování databáze.
Menu administrace slouží konkrétně k:
definování uživatelů aplikace
modifikaci (úprava, výmaz, změna hesla) uživatelů aplikace
modifikaci vzhledu aplikace (uživatelské nastavení aplikace)
definici přístupu uživatele k jednotlivým objektům aplikace
přehledu o zpracovaných vstupních souborech
přehledu o zpracovaní jednotlivých jobů
přehledu o chybách ve vstupních souborech
prohlížení globálního logu aplikace
zálohy databáze aplikace
další administrační úkony spojené s provozem aplikace
odhlášení z aplikace